
Google Indexes Without Links or Sitemaps
I have long been convinced that Google uses its many tools to find and queue urls for indexing, but I believe I have found indisputable proof. After beginning many of our experiments using the our sitemaps technique (using Google Sitemaps to get pages indexed in order to control for the unpredictable weight of individual links), we noticed a trend.
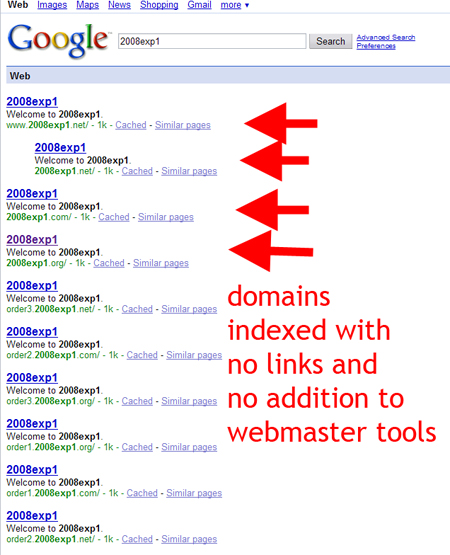
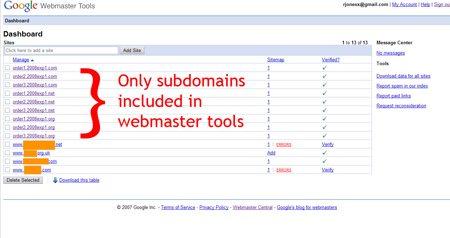
When using webmaster tools to get subdomains indexed, the domains themselves kept getting indexed. We painstakingly made sure that no URLs were ever linked to, much less the domains themselves which can and do interrupt the quality of our results.
Nevertheless, Google still finds a way. While I think there is no real problem with this practice, it does seem clear that Google will attempt to spider all parts of a URL…. ie: if you were to get http://subdomain.domain.com indexed, Google – without any other prompting or links, would attempt to index http://domain.com
Strangely enough, google found both the www and non-www version of the 2008exp1.net domain. From my server logs, I can say unequivocally that the only visitors to this version of the domain were myself and googlebot. I do, however, surf with Google Toolbar open and running at most times. I do not have clear evidence at this point to determine whether Google queues up with and without the www on its own, or if the toolbar prompted it to after I had visited it.
8 Comments
Trackbacks/Pingbacks
- Linky Goodness, February 21 - [...] Could it be true? Google Indexes Without Links or Sitemaps [...]
- Hubhit - Google Indexes Without Links or Sitemaps... I have long been convinced that Google uses its many tools to find…
Submit a Comment


{kind=link}
Google now treats subdomains just like a sub-folder on the site. They are no longer treating subdomains as separate sites.
This is why I don’t use the Google Toolbar. Everything that the toolbar can see, Google can see.
Yeah, run in the same problems by using google toolbar once. I am 100% sure, that google uses toolbar data to check if they got page in index, and if not, they try to crawl it.
Run in big problems due that, and some computer geeks unability to code, as it tried to index content noone else should access to.
Btw, use .htaccess redirection if you are use apache to make sure that people from one domain would redirected with 301 to another. Its quite simple and there are examples on net. If you do not use apache, you might have to use other solutions (checking that with php/asp in each of your pages header, for example).
The also pick up on content and domains through products like gmail and google docs. Everything is being index, so it is not just about not having a link to website. You must properly block all bots before ever going live with a domain, if that is your intention.
Over a year ago we tested the toolbar’s most hidden feature: indexing. Ever wondered how can Google index pages with no links to them? Well, here is how it’s done: if you are browsing the web with the toolbar installed, (I am not saying just visible or enabled), Google is recording every page you visit and simultaneously checking to see if the address to it is in the index or not. So what if its not? It will be indexed on the next schedule. If you don’t want a page to get indexed yet, the make sure you don’t have the toolbar installed in your browser while getting it ready. We have browser with and without the toolbar depending on what we are working. Great info by the way.
Another strange this is that I have registered a number of domains and not added a sitemap, and they are being found and ranked. Spoke with a domain industry leader and apparently Google has developed quite a taste for Zone files on tlds domains such as .com, .net, .org
i dont use GMail, or Toolbar and have never visited these sites just registered them and they are index almost automatically.
I can confirm your findings. I have had sites indexed within 24 hours of putting content on a newly registered domain with no history, inbound links or account on GWT.