
PowerSet Will Never Be a Google Killer
Many of you have seen the recent stories about Powerset releasing its public beta. First off, I must say that they have done a great job on an interesting product. However, I think we need to quickly – and I mean very quickly – put to rest this conversation that Powerset could EVER be a Google Killer. ** Please Read the Comment below from Mark at PowerSet for their side of the story **
- It takes Powerset a month to index and analyze just Wikipedia – 1/8000 of the web. (Mark from Powerset Disputes this Claim Below and, unfortunately, I have no way to verify one way or another. That being said, even a couple of days to handle a site like Wikipedia which has similar formatting across the entire domain is slow in comparison to a giant like Google) Even if their semantic engine were flawless, it would be accurate for year old information at best. Powerset may carve out a niche in the research market, especially research for 9 year olds who are still at the age were citing Wikipedia won’t get you an automatic F. However, for the average person, there is an expectation that information on the Web, and available through the search engines, is at least somewhat current. How is Powerset going to explain to the web world that they haven’t indexed Twitter yet because they just haven’t gotten to it?
- Semantic engines may be good for understanding content, but not for understanding that content’s importance. This is where the link algorithm matters – something Google realized a decade ago. In most cases, the answer you are looking for is available in quite a few places – Google is just exceptionally good at finding the one that is trustworthy.
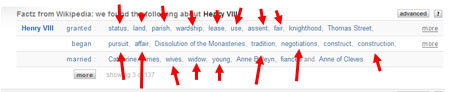 For example, in the above picture, you can see all of the single n-gram results that have been given to us via the superior Powerset semantic engine. We can learn that Henry the VIII married Wives, for example. And that He Granted Use. Awesome.Bear in mind, this is the example, of all the possible examples, that Powerset chose to feature on their homepage.
For example, in the above picture, you can see all of the single n-gram results that have been given to us via the superior Powerset semantic engine. We can learn that Henry the VIII married Wives, for example. And that He Granted Use. Awesome.Bear in mind, this is the example, of all the possible examples, that Powerset chose to feature on their homepage. - Semantic searches are slow. The single greatest asset Google has had, in my opinion, has been the speed of their search results. I know, they have good results, but for many years Google was so fast that even if you didn’t find the results you wanted, you could search it again and again and again in half the time it would take another search engine that got it right the first or second time around.
 For example, in the above picture, you can see all of the single n-gram results that have been given to us via the superior Powerset semantic engine. We can learn that Henry the VIII married Wives, for example. And that He Granted Use. Awesome.Bear in mind, this is the example, of all the possible examples, that Powerset chose to feature on their homepage.
For example, in the above picture, you can see all of the single n-gram results that have been given to us via the superior Powerset semantic engine. We can learn that Henry the VIII married Wives, for example. And that He Granted Use. Awesome.Bear in mind, this is the example, of all the possible examples, that Powerset chose to feature on their homepage.I don’t have any problems with Powerset, per se. I think they have invented a neat search engine that will be useful in certain sectors. However, they need to actively squash the “Google Killer” mindset that is circling the internet. What they don’t realize is every time someone visits their site because they saw one of these “Google Killer” articles, they are disappointed.
One of the key strategies of marketing is to lower the expectations so that you can spin whatever happens into a victory. Why do you think that Google calls products like Gmail (that you and I would consider as polished as any app we have ever created) “Beta”? It is because they know that if people expect a beta, and see a professional app, they are going to be convinced to stay. Powerset is setting themselves up for a huge loss if they allow this kind of marketing to continue.
No tags for this post.3 Comments
Submit a Comment


{kind=link}
Thank you for your interesting article! 🙂
I am a search architect and I have been developing, integrating, deploying and maintaining search engine technology since 1997.
I’m not familiar enough with PowerSet yet to say whether or not its a Google Killer, but I did want to comment on points #1 and #3.
#1 Slow Data Import: I greatly doubt the this short-coming will persist for long and probably has more do (a) hardware budget allocation and (b) crawler politeness than anything else.
a) Hardware Budget: In systems I administer, there are machines used as crawlers, document processor, indexers, search and query nodes. We often spend more on indexer/search machines than we spend on crawler machines. Since it is a beta, they probably don’t have the full compliment of crawlers they plan to use in the future. If they use a distributed crawler architecture, you can resolve the problem by adding more hardware. During the beta, however, why incur additional hardware expenses until you are able to gauge demand and react accordingly?
b) Crawler Politeness: You state that it takes PowerSet months to index and analyze Wikipedia. It may not be POLITE for them to crawl and index Wikipedia any faster. If someone has a multi-threaded, distributed crawler they could direct it to crawl Wikipedia as fast as possible but from Wikipedia’s perspective it might end up looking like something else: A Denial of Service attack. Regardless of crawler bandwidth, if a crawler fetches documents too aggressively it can consume available bandwidth for normal users and possibly even bring the site its crawling down.
Since Wikipedia has a lot of visitors, lets say a “polite” crawling rate is fetching 4 documents a minute. If Wikipedia has around 750,000 articles, it would take 187,500 minutes, or 3125 hours, or 130 days, or roughly 4.3 months to just *fetch* the content for indexing.
Judging PowerSet to be “slow” based upon crawl time to just one website (while it might be crawling millions more concurrently) isn’t a great way to measure overall performance. After the initial population of data, refreshes can go quickly if a web server properly report last modification dates because only documents that have changes are grabbed and reindexed.
#2 Semantic Searched Are Slow: Yes, Semantic Searches are slower in general than statistical TF-IDF or Bayesian algorithms. However, how slow is too slow? In my experience, you want sub-second search results to give enough time for transforming/rendering HTML output. If it takes more than 2-3 seconds, folks start to get wanderlust. If PowerSet search results are too slow currently, that is often something that can be remedied with hardware, as I mentioned above. Server hardware, especially *managed* hardware, ESPECIALLY *fault-tolerant* *fully-redundant* *managed* hardware can be expensive. As it is a beta, after they are able to gauge demand they will probably scale accordingly.
Anyways, I just wanted to give some feedback since it may not be as simple as it appears.
Cheers!
-Michael McIntosh
If you have any ideas about how to stop people from calling us a Google-killer, please let me know. I’d be happy if people just turned to Powerset, for now, as a a better experience for reading Wikipedia content.
It only takes us a few days to analyze Wikipedia.
And note that the extracted Factz that you show aren’t “n-grams”– those are actually derived from the linguistic structure of sentences. Click on a few of the terms to see the syntactic variation from which the Factz are derived.
Good write up. I would love to see another search engine come in and do really well. With the Microhoo stuff lately I think that door is wide open, but I think you are right that this one will not catch Google and not even beat Ask.